

Testing Your LLM Applications (Without Going Broke)

A few weeks into my LLM project, I needed to write tests for a resume parsing function I was building. Not the “run it manually and hope all is well” kind of testing - actual automated tests that could run in CI/CD.
The function called OpenAI’s API. Which costs money 🤑. And returns different outputs each time.
My first attempt? I just called the API directly in my tests. Wrote five test cases, ran pytest, watched my terminal fill with API calls. Tests took 45 seconds. Then I checked my OpenAI dashboard: $0.50 gone.
That adds up fast. Run tests 20 times a day during development? $10/day. $50/week. $200/month. That’s just me. Scale to a team of five? $1,000/month on test runs.
There’s a better way.
What We’re Fixing
Quick recap from Part 1: one of our problems was that we couldn’t test LLM code without literally calling the API. That made our tests expensive, slow, and flaky.
Now that we’ve got structured prompts and type safety from Part 2, we can build a proper testing strategy. Today we’ll:
Learn how to test LLM code without calling APIs (mocking and test doubles).
Understand the difference between unit tests and integration tests (and when you need each).
Test that your prompts truly work (evaluation suites).
Set up test infrastructure that doesn’t suck.
Most of what I’m covering works whether you use BAML or not. These are software engineering principles that apply to any LLM application. BAML just makes some of it easier.
Why Testing LLMs is Different
Traditional software is deterministic. Same input, (hopefully) same output, every time.
def add(a, b):
return a + b
# This passes every single time
assert add(2, 3) == 5LLMs? Non-deterministic by design. Same input, different output. Even with temperature=0, you get variations.
And it gets weirder: with traditional software, you test your code. With LLMs, you’re also testing your prompts. Is the bug in your code or your prompt? Sometimes you can’t tell.
I’ve seen tests that pass 8 times out of 10. The other 2? The LLM formats the response slightly differently and the parsing breaks. That’s not a code bug. That’s a prompt engineering problem disguised as a testing problem.
So we need a testing strategy that handles both: testing our code works correctly AND testing our prompts produce useful outputs.
Universal Testing Principles
I’ll show you the core testing principles first, using plain Python. This works whether you’re using BAML, LangChain, raw OpenAI calls, or building your own abstractions.
Don’t Test the LLM, Test Your Code
You don’t need to test the LLM itself. OpenAI already tested GPT-4. You need to test YOUR code that wraps the LLM.
Here’s our original resume analyzer (simplified) 👇🏾
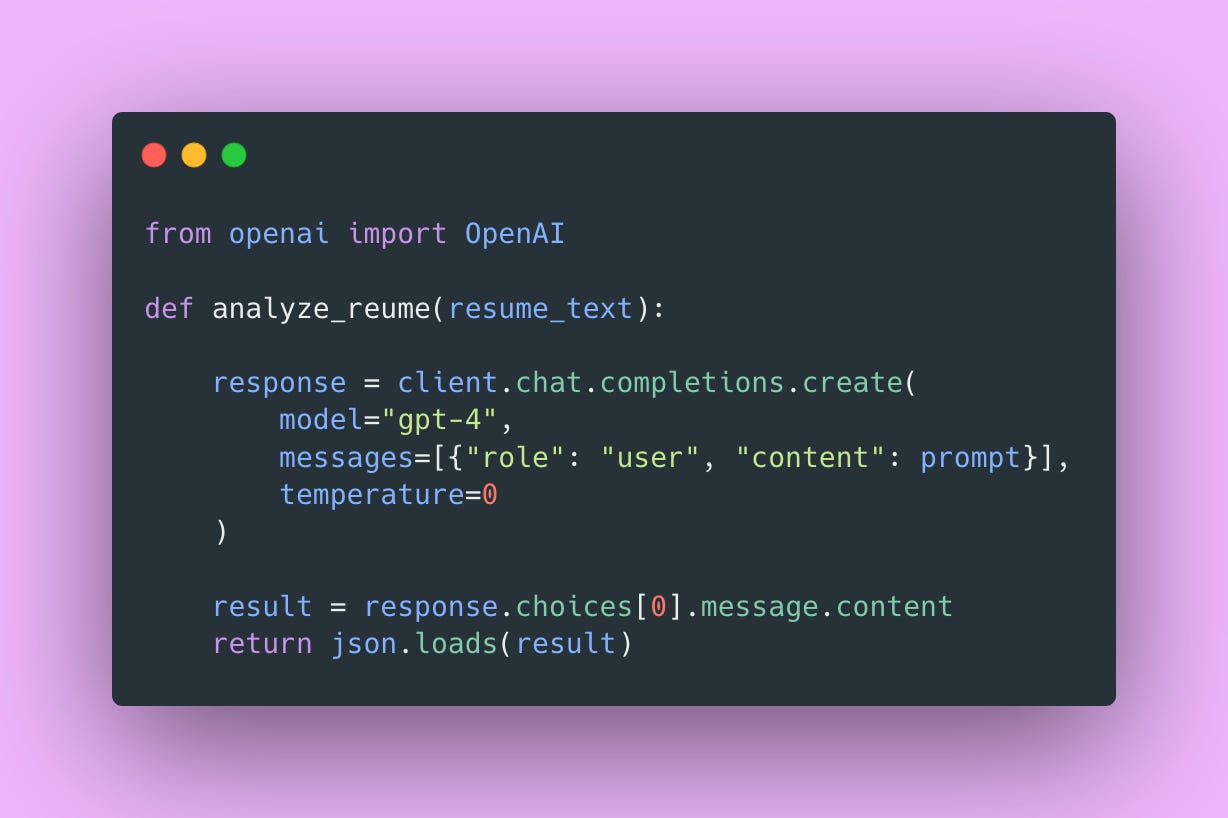
The problem: every time you test this, you hit the OpenAI API. Expensive and slow.
The solution: dependency injection. Make the LLM client something you can swap out.
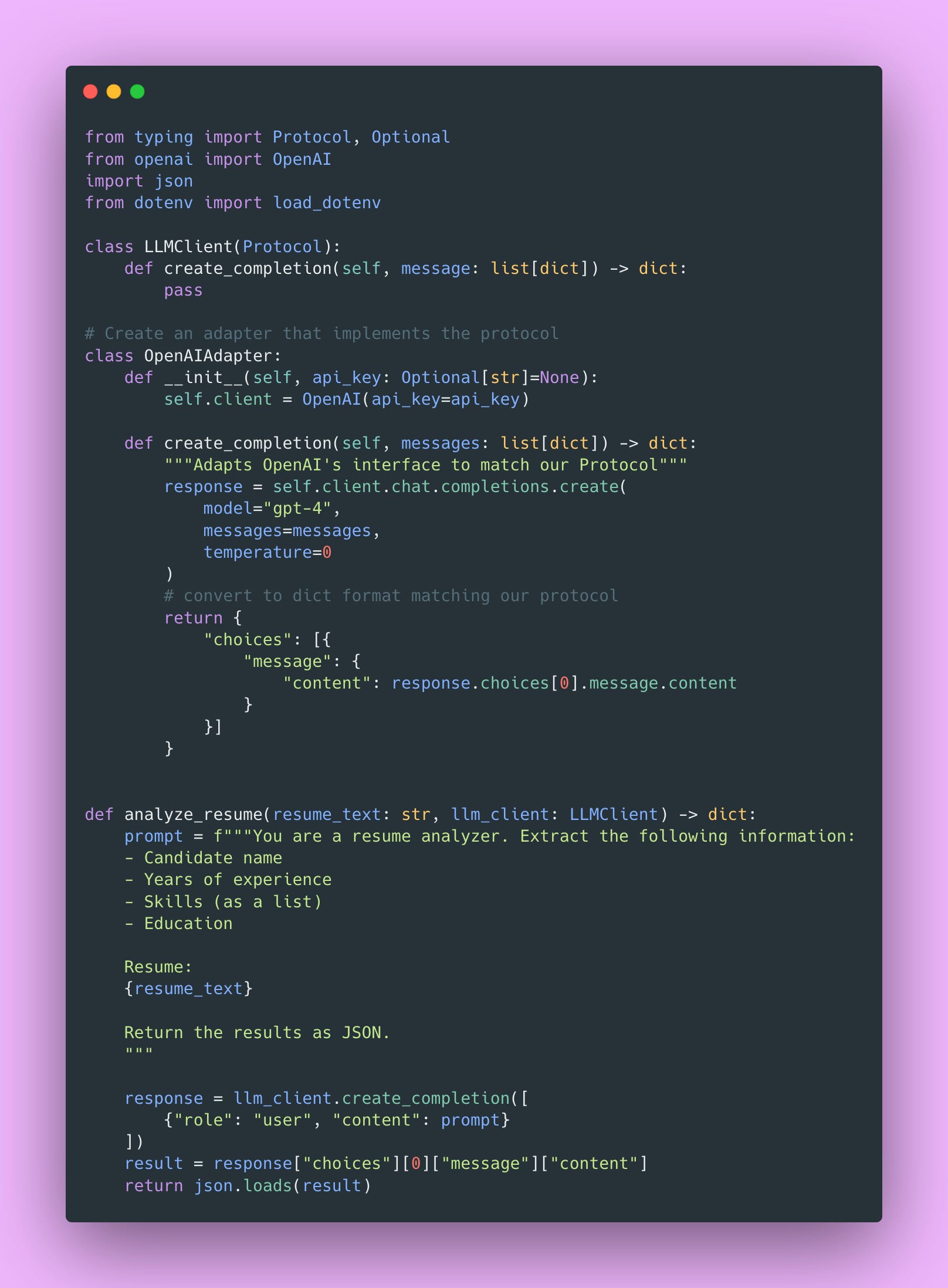
Now in your tests, pass in a fake client.
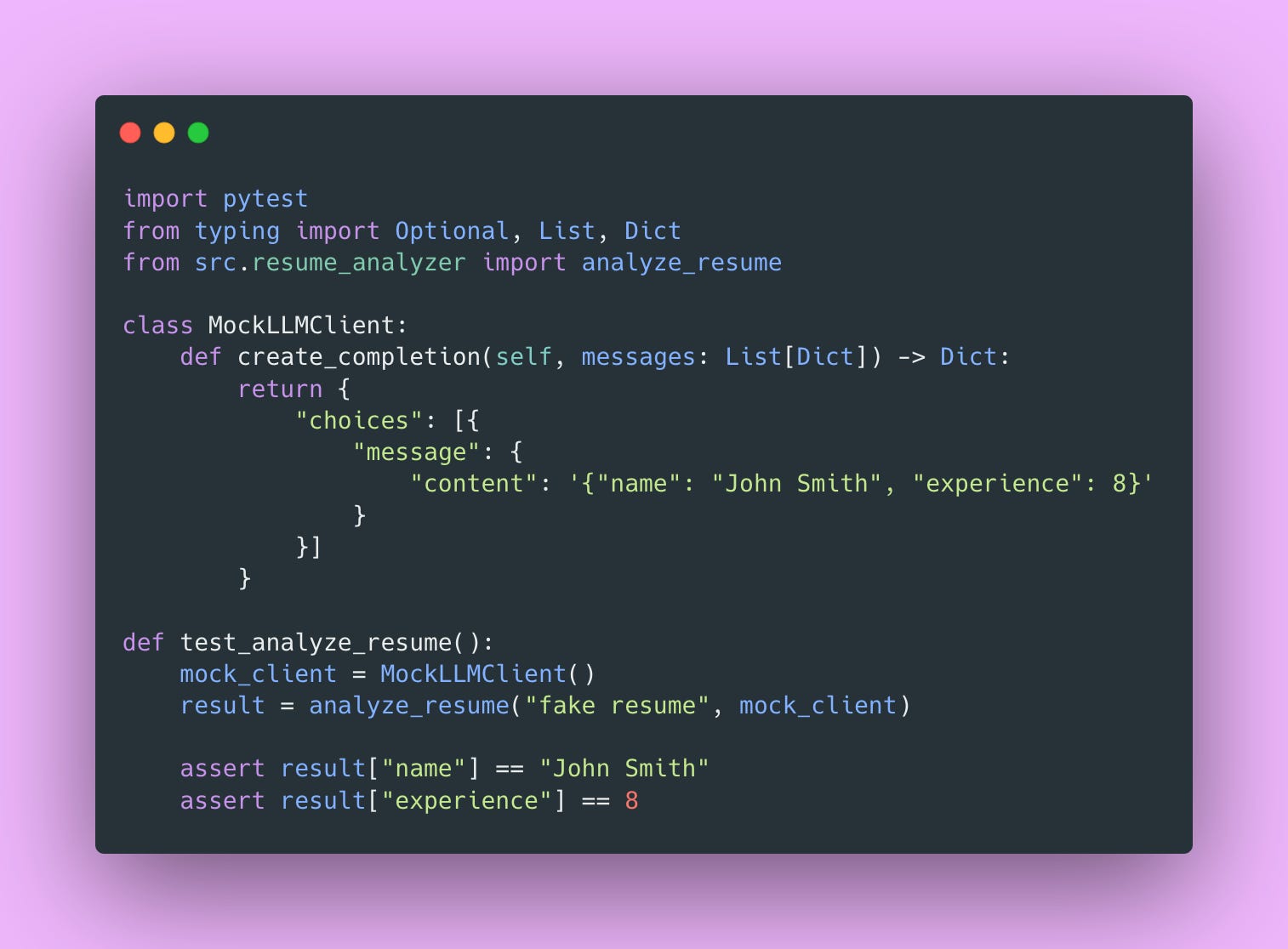
No API calls. No cost. Runs in milliseconds.
This is the fundamental pattern: separate the “call the LLM” part from the “process the result” part.
Build Different Mocks for Different Scenarios
One mock isn’t enough. You need mocks for different scenarios.
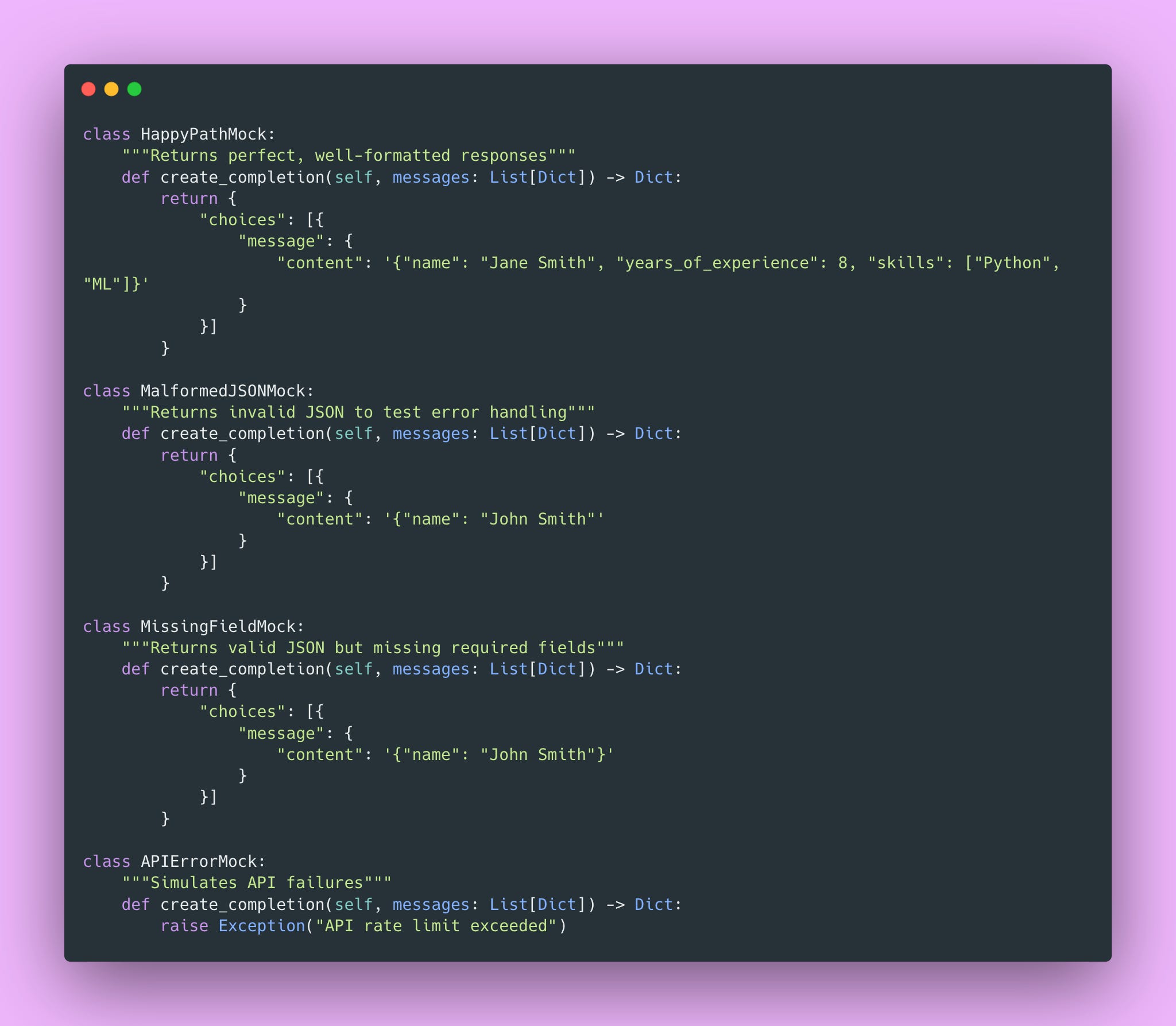
Now you can test all the edge cases.
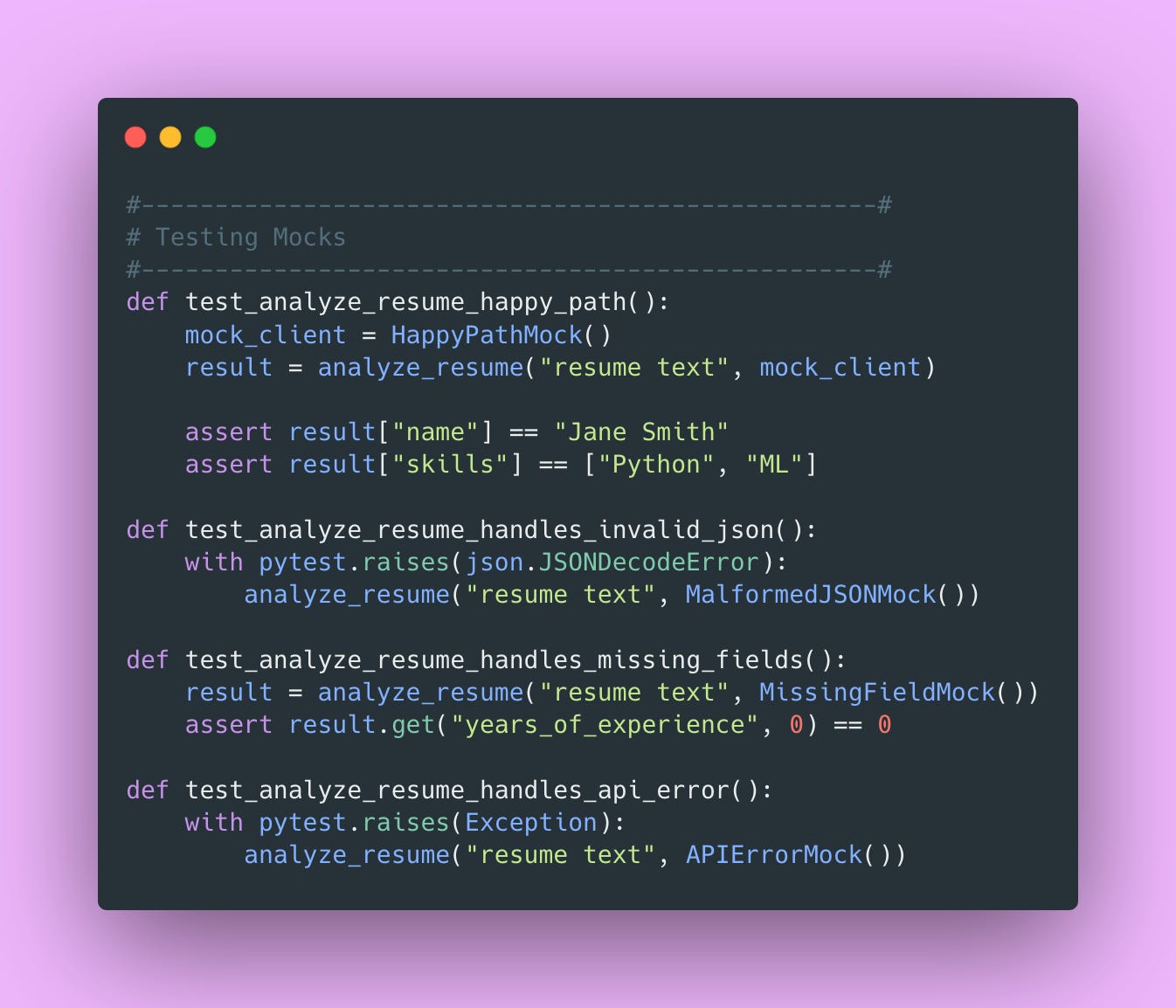
This builds confidence that your error handling actually works, without spending money on API calls.
📝 Note: Testing error handling is especially important for LLM applications because LLMs can return unexpected formats. If your error handling isn’t tested, you won’t discover the bugs until production (been there, learned that lesson the hard way).
Property-based Testing
Sometimes you don’t care about the exact output. You care about properties of the output.
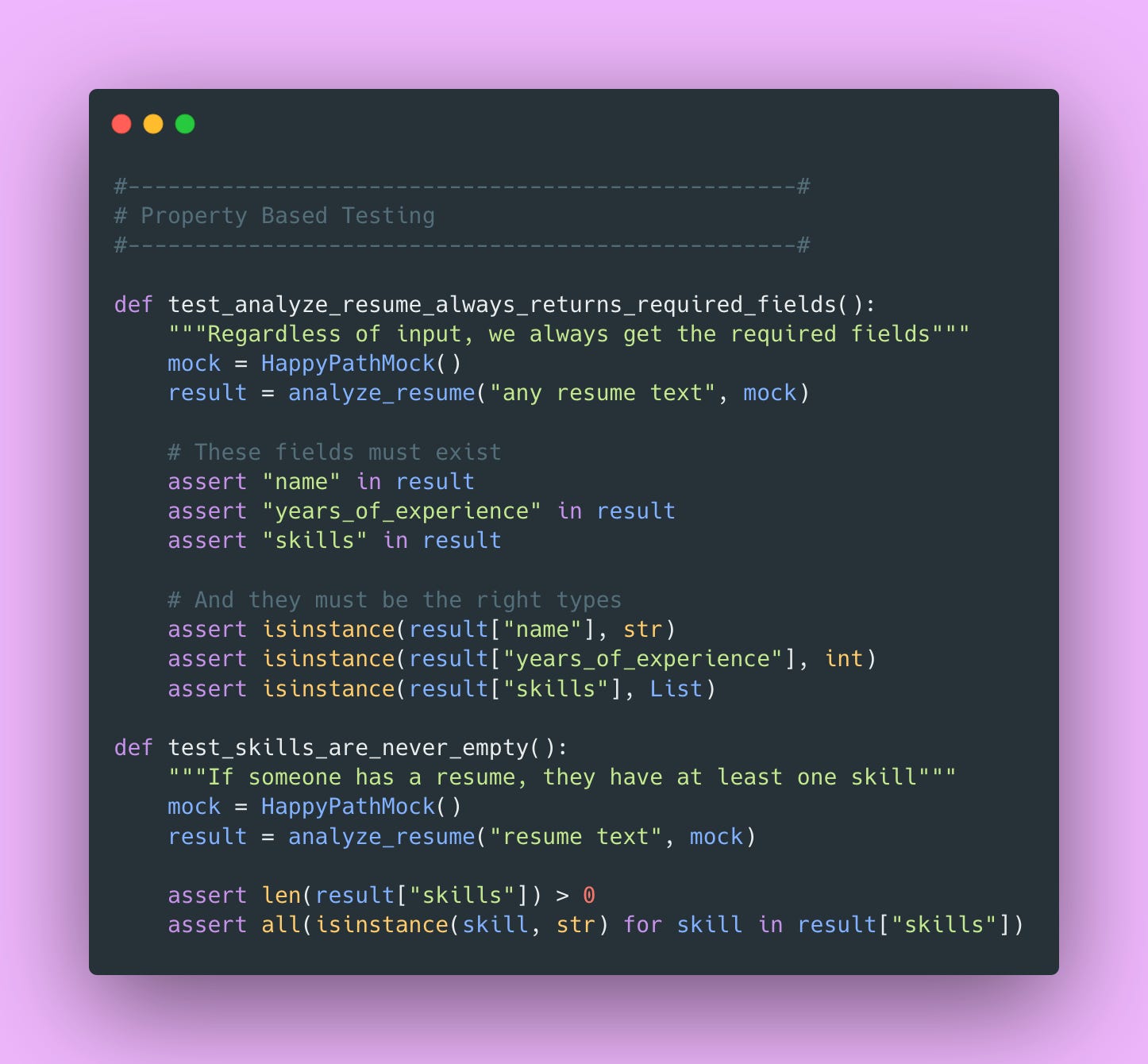
This type of testing is about invariants: things that should ALWAYS be true. It’s less brittle than testing exact outputs, which is perfect for LLM applications where exact outputs vary.
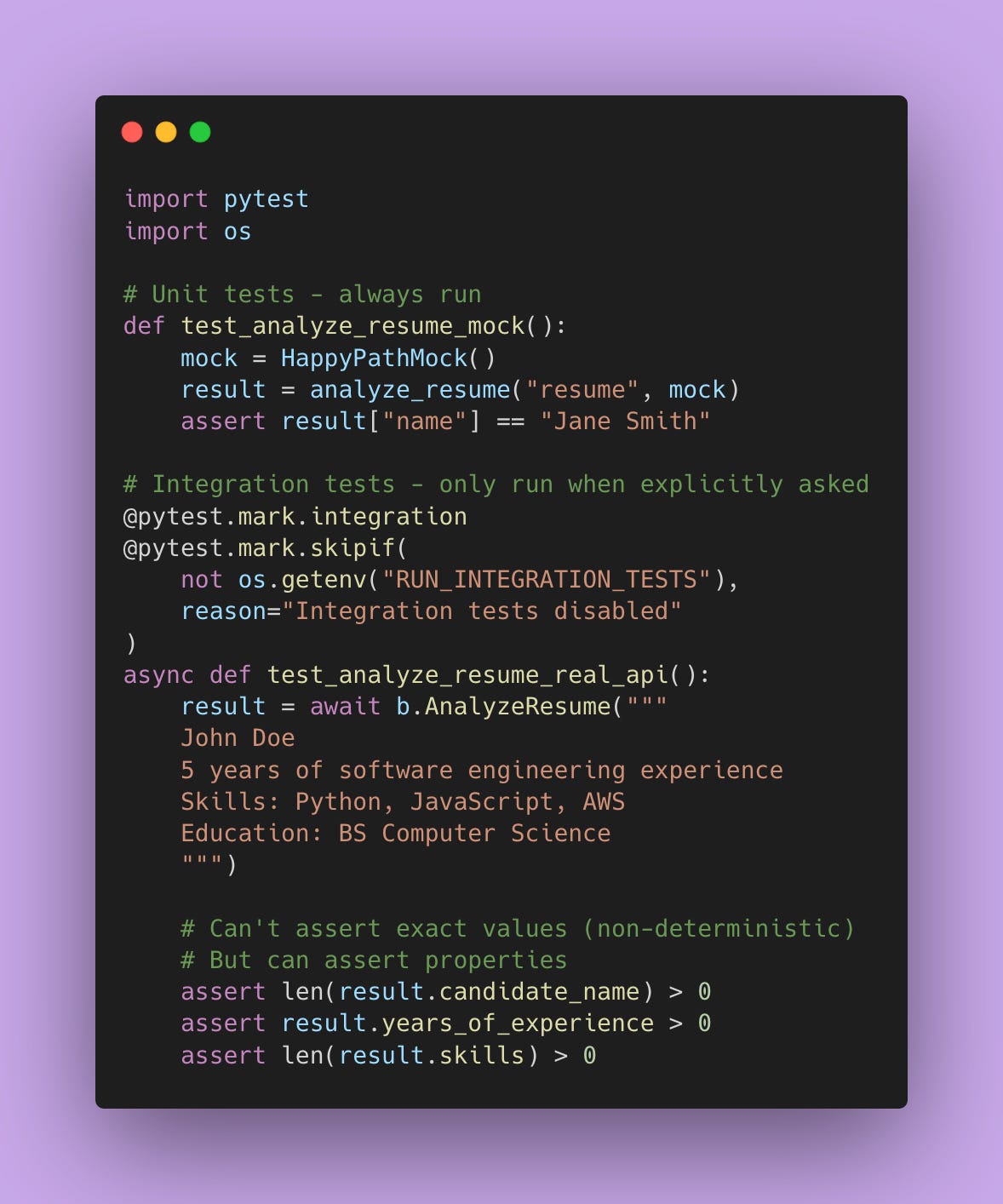
Integration Tests vs Unit Tests
Mocks are great. But at some point, you need to test that your code works with the real API.
Unit tests: Fast, cheap, test your code in isolation using mocks. Run these on every commit.
Integration tests: Slow, expensive, test that your code actually works with real APIs. Run these less frequently (once a day or before releases).
Here’s how I’d structure these tests 👇🏾
Running Tests Locally
During normal development, you want fast feedback. Run just the unit tests:
pytestThis runs in seconds, costs nothing, and catches most bugs. You’ll run this dozens of times a day as you write code.
When you’re about to commit or merge a feature, verify the integration works.
RUN_INTEGRATION_TESTS=1 pytestThis hits the OpenAI API. Takes a minute or two. With 5-10 integration tests, you’re looking at $0.10-0.50 per run depending on your prompt complexity and which model you’re using. You run this maybe once or twice before pushing your code.
You can also run just the integration tests.
RUN_INTEGRATION_TESTS=1 pytest -m integrationThis is useful when you’ve changed your prompt and want to verify it works with the real API, but don’t want to wait for all the unit tests to run again.
Setting up CI/CD
In CI/CD, run unit tests on every PR, but integration tests only on the main branch or before releases.
This way you’re not burning money on API calls during development, but you still have confidence that the integration works.
Evaluation Suites for Prompt Quality
You need to test your prompts separately from your code.
A prompt evaluation suite is a collection of real examples with known correct outputs. Like a test dataset, but for your prompts.
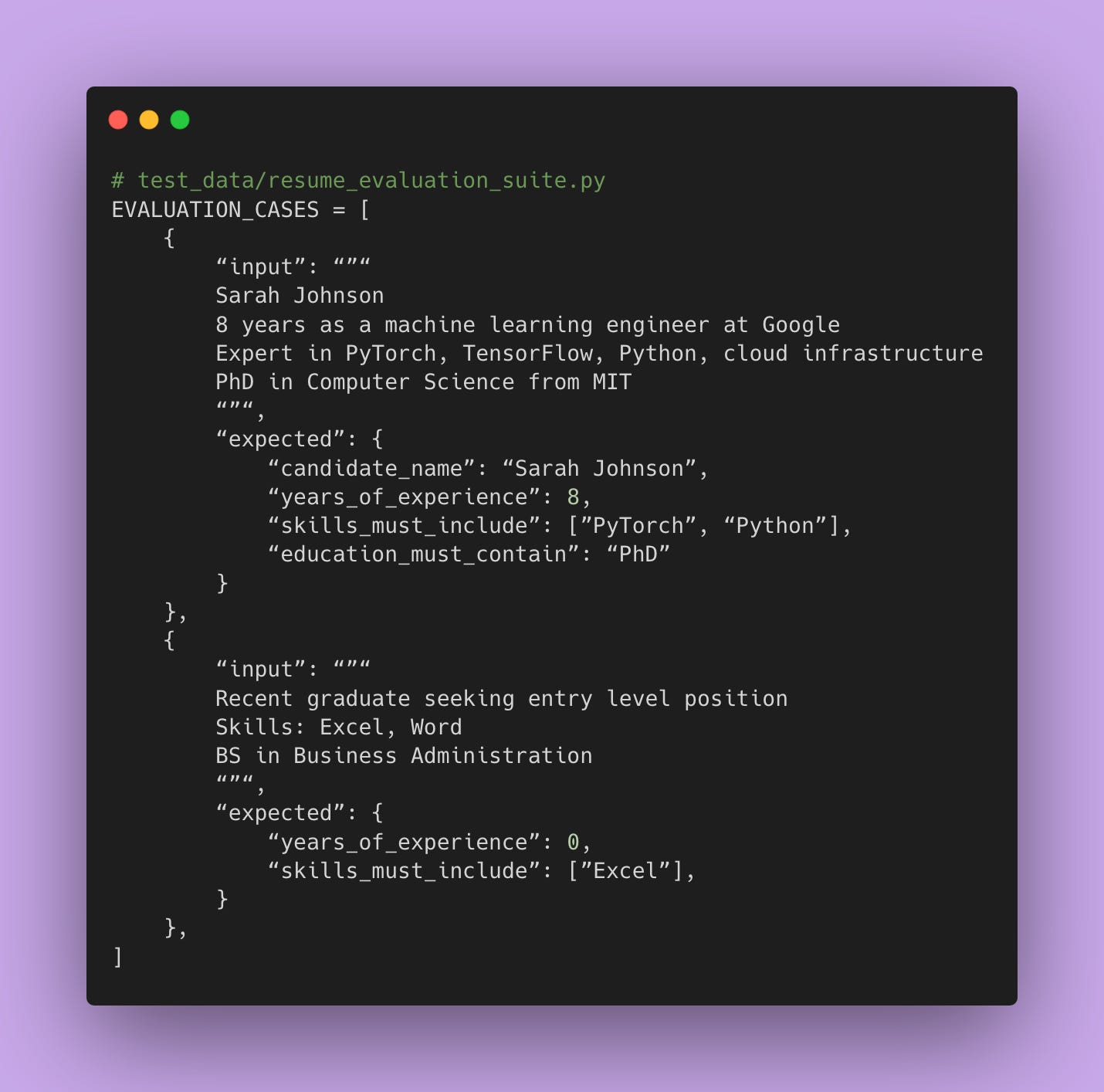
Test your prompt against all of them.
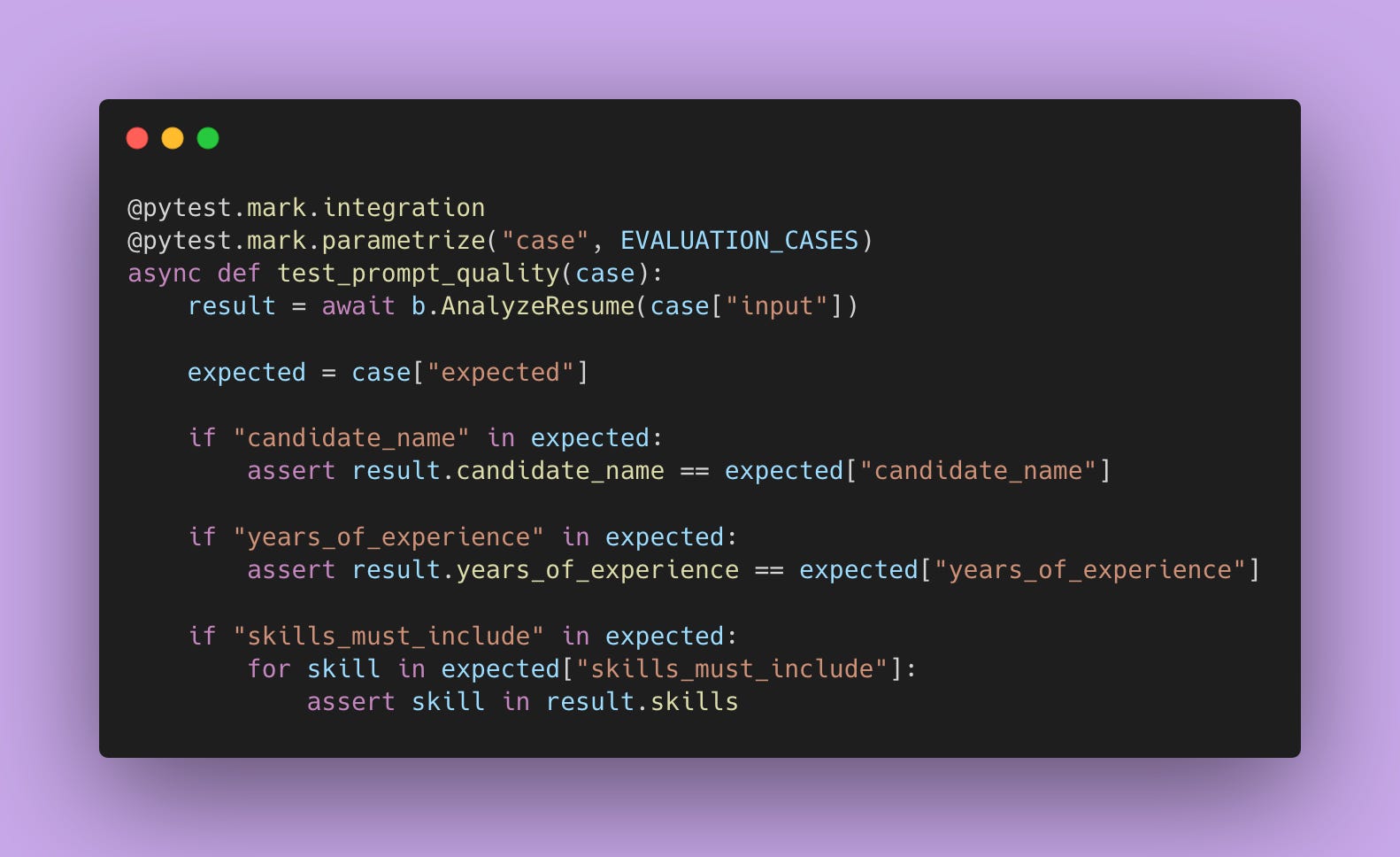
When you change your prompt, run this evaluation suite. If your pass rate goes down, you made the prompt worse. If it goes up, you made it better. Iterate on prompts scientifically instead of guessing.
💡 Pro Tip: Start your evaluation suite small (5-10 cases) and add to it over time. Don’t try to create a comprehensive eval suite on day one.
Regression Testing
Every time you find a bug in production, add it to your test suite.
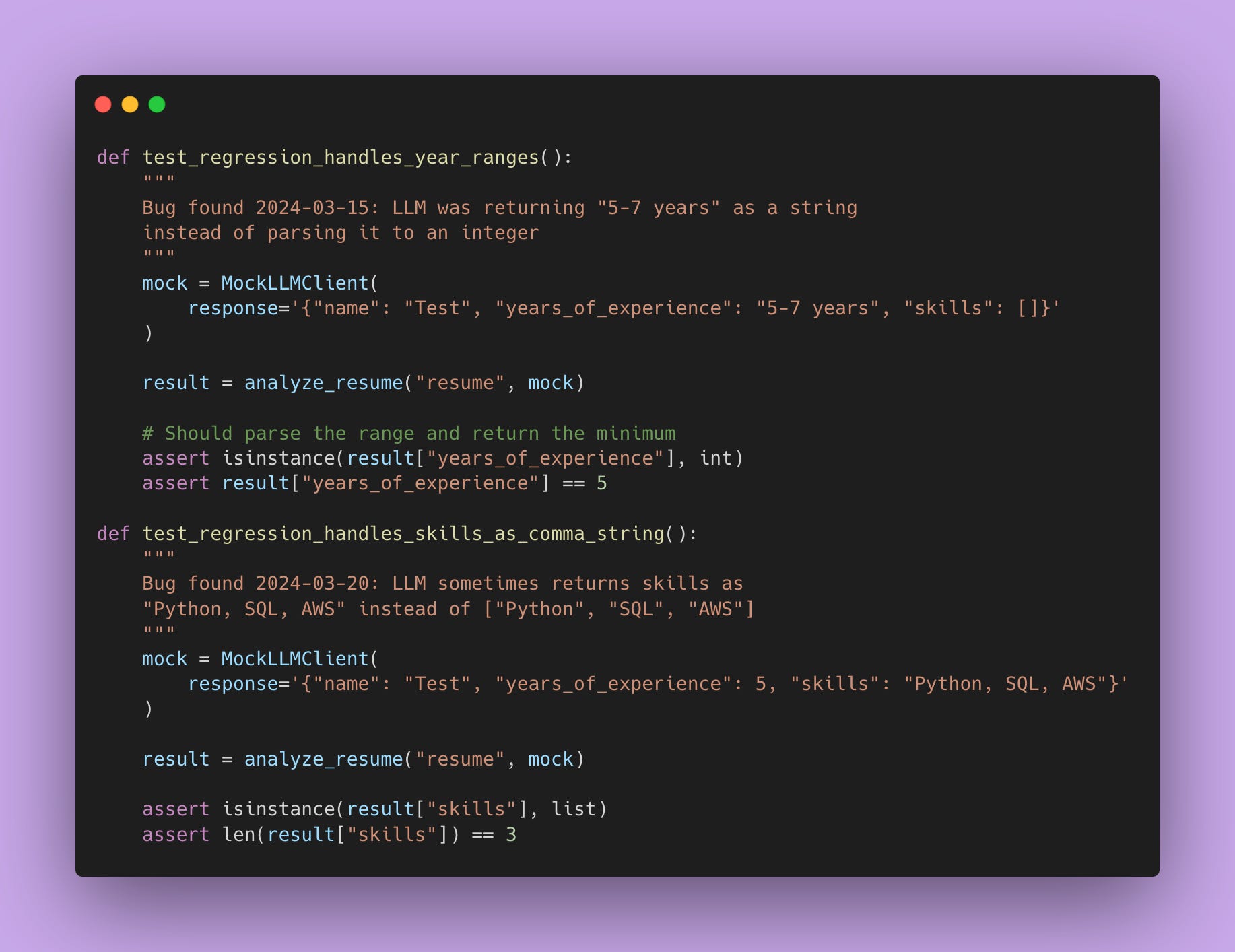
These tests document what went wrong and ensure it doesn’t happen again. Plus, they’re documentation for your team about quirks in the LLM’s behavior.
Setting Up Test Infrastructure
Directory Structure
my-llm-project/
├── baml_src/
│ └── resume.baml
├── src/
│ └── resume_analyzer.py
├── tests/
│ ├── unit/
│ │ ├── test_resume_analyzer.py
│ │ └── mocks.py
│ ├── integration/
│ │ └── test_resume_analyzer_integration.py
│ └── evaluation/
│ ├── test_prompt_quality.py
│ └── evaluation_suite.py
├── pytest.ini
└── requirements-dev.txt
pytest.ini
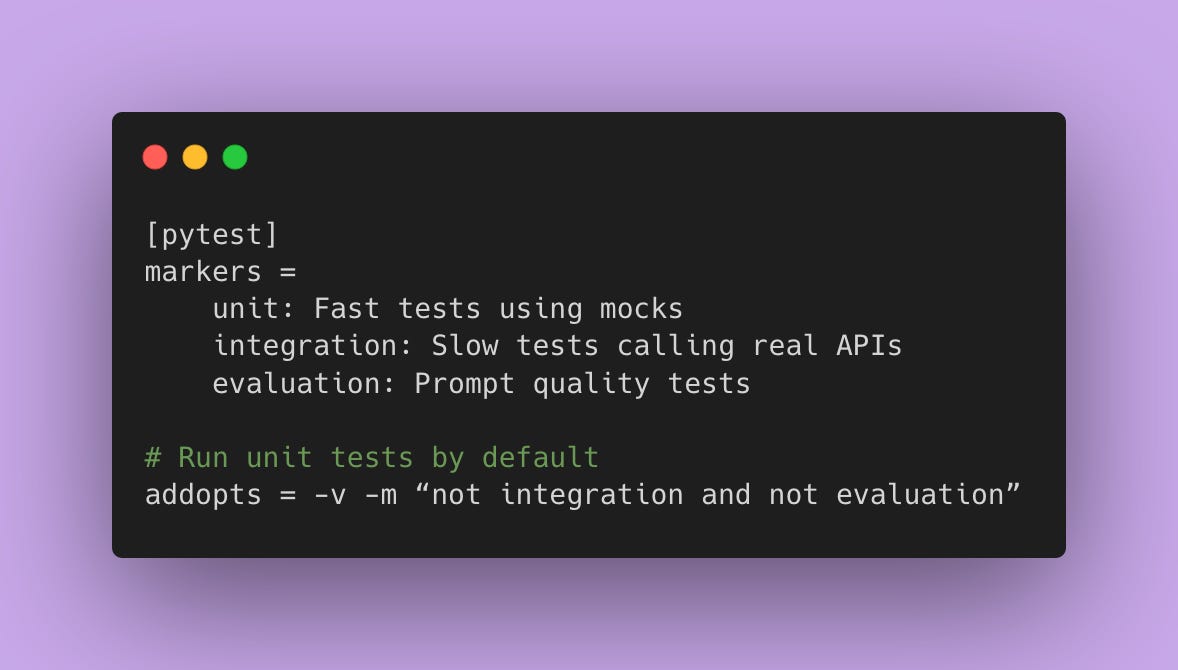
Running Different Test Suites
# Default: only unit tests
pytest
# Include integration tests
pytest -m “unit or integration”
# Run full evaluation suite
pytest -m evaluation
# Run everything
pytest -m “”In CI/CD (GitHub Actions)
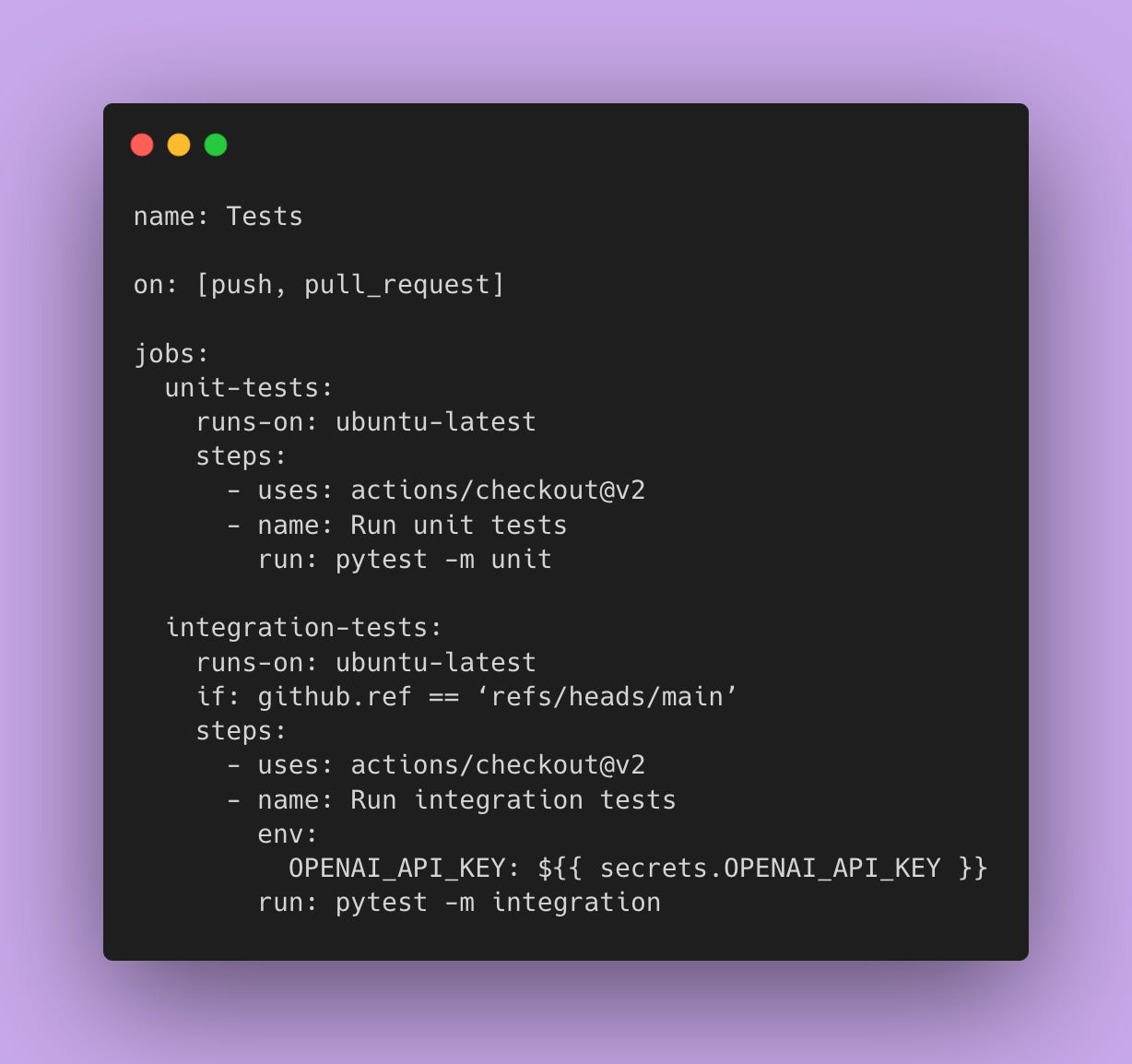
This setup gives you fast feedback during development (unit tests) while still having confidence that integration works (integration tests), without burning through your API budget. (No more wasting $5-10 every time someone pushes a typo fix 🔥💰).
What Good Looks Like
My rule of thumb for a well-tested LLM application is:
80%+ unit test coverage - Test your code logic with mocks.
5-10 integration tests - Verify real API calls work for critical paths.
10-20 evaluation cases - Test prompt quality against real examples.
Regression tests for every production bug - Ensure bugs stay fixed.
Unit tests run in seconds and cost nothing. Integration tests run in minutes and cost a few cents. Evaluation tests cost a bit more but give you confidence in your prompts.
The mock-based approach is both cheaper AND more thorough than running all tests against the real API.
Your Homework
Pick that function you converted to BAML in Part 2 (or any LLM function you have). Write:
One happy path unit test - Mock a perfect response, verify your code handles it.
One error handling unit test - Mock a bad response, verify your error handling works.
One property-based unit test - Test that certain properties are always true.
One integration test - Call the API with a real example.
If you don’t have a function yet, use this example.
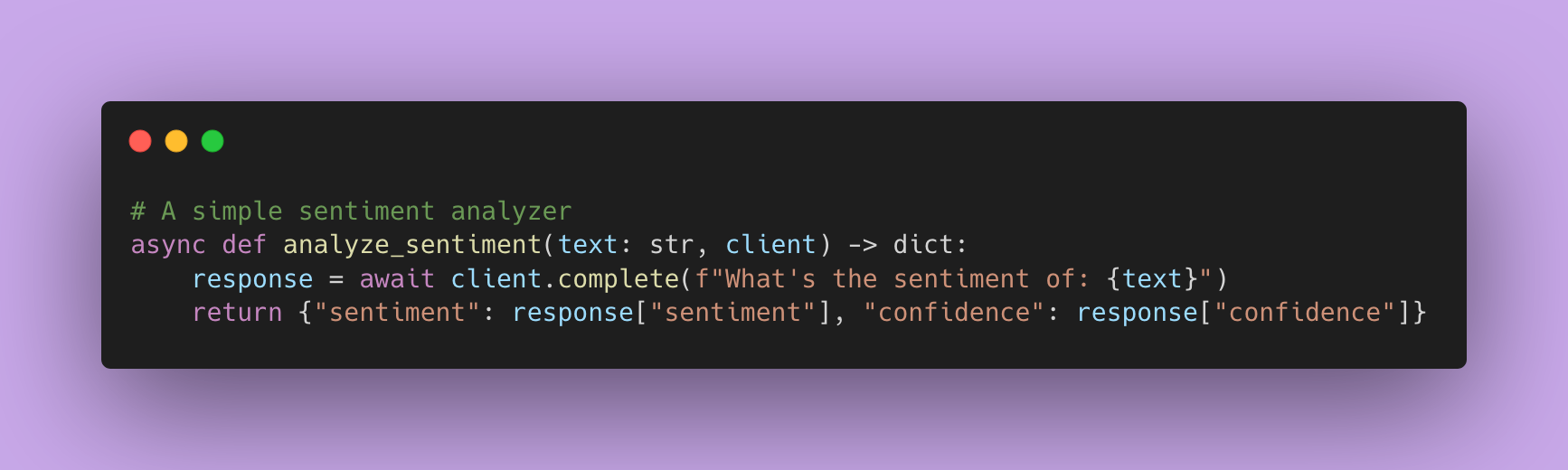
Write those four tests. I mean it! The muscle memory matters.
⭐️ Bonus: Set up pytest markers so you can run your unit tests separately from integration tests. This will save you time and money as your test suite grows.
Next post: Part 4 on self-hosting LLMs with vLLM. Because once you’ve got type-safe prompts (Part 2) and comprehensive tests (Part 3), you might start thinking “what if I didn’t have to pay OpenAI for every single request?”
See you there 🥾