

The Six Problems Hiding in Your LLM Notebook Code


I’ll never forget the first time I got an LLM to work locally. I was messing around with HuggingFace’s transformers library, running a sentiment analysis model on some text data. The model actually worked! It classified my test sentences correctly, the output looked reasonable, and I felt accomplished ☺️!
Not to mention the timing worked out well. My team had been talking about adding some LLM capability to one of our features for a few sprints. We kept deprioritizing it, moving it around in the backlog. Eventually, my tech lead asked if anyone wanted to spike it and see if it was feasible.
I volunteered. I mean, I’d just spent a weekend playing with transformers anyway, so why not?
I spent a few days tinkering in a Jupyter notebook. Got a basic prototype working, and showed it to people on my team during a sync. Everyone thought it was pretty cool. The PM got excited and my manager seemed interested. Apparently this prototype was what we needed.
Then sprint planning rolled around the next week.
“Okay, so the spike is done,” the PM said, pulling up the ticket. “How many story points would it take to actually build this properly?”
I stared at my screen. My brain went completely blank.
“Uh…more than 5?” I said. “Maybe 13? Honestly, I have no idea.”
And I really didn’t. My prototype was a 150-line Jupyter notebook with hardcoded API keys and string manipulation. How much work sits between “it works in my notebook” and “this is production-ready”?
Spoiler: a lot.
Why Notebooks Fail in Production
This isn’t a criticism of notebooks. I love using Jupyter notebooks or Google Colab! They’re perfect for experimentation, quick iterations, and showing your work. But there’s a massive gap between “it works in my notebook” and “this is ready to serve real traffic.” If you come from a data science or research background, you might not even know what that gap looks like yet.
This series bridges that gap. We’re going to take a messy notebook with LLM code and transform it into a production-ready system. No hand-waving, no shortcuts. We’ll cover type safety, testing, self-hosting, deployment, and everything else that separates a prototype from a product.
But first, we need to honestly assess the problem. Let me show you what makes notebook code so problematic for production systems.
The Mess We’re Starting With
Here’s what a typical “I just need to get this working” LLM notebook looks like.
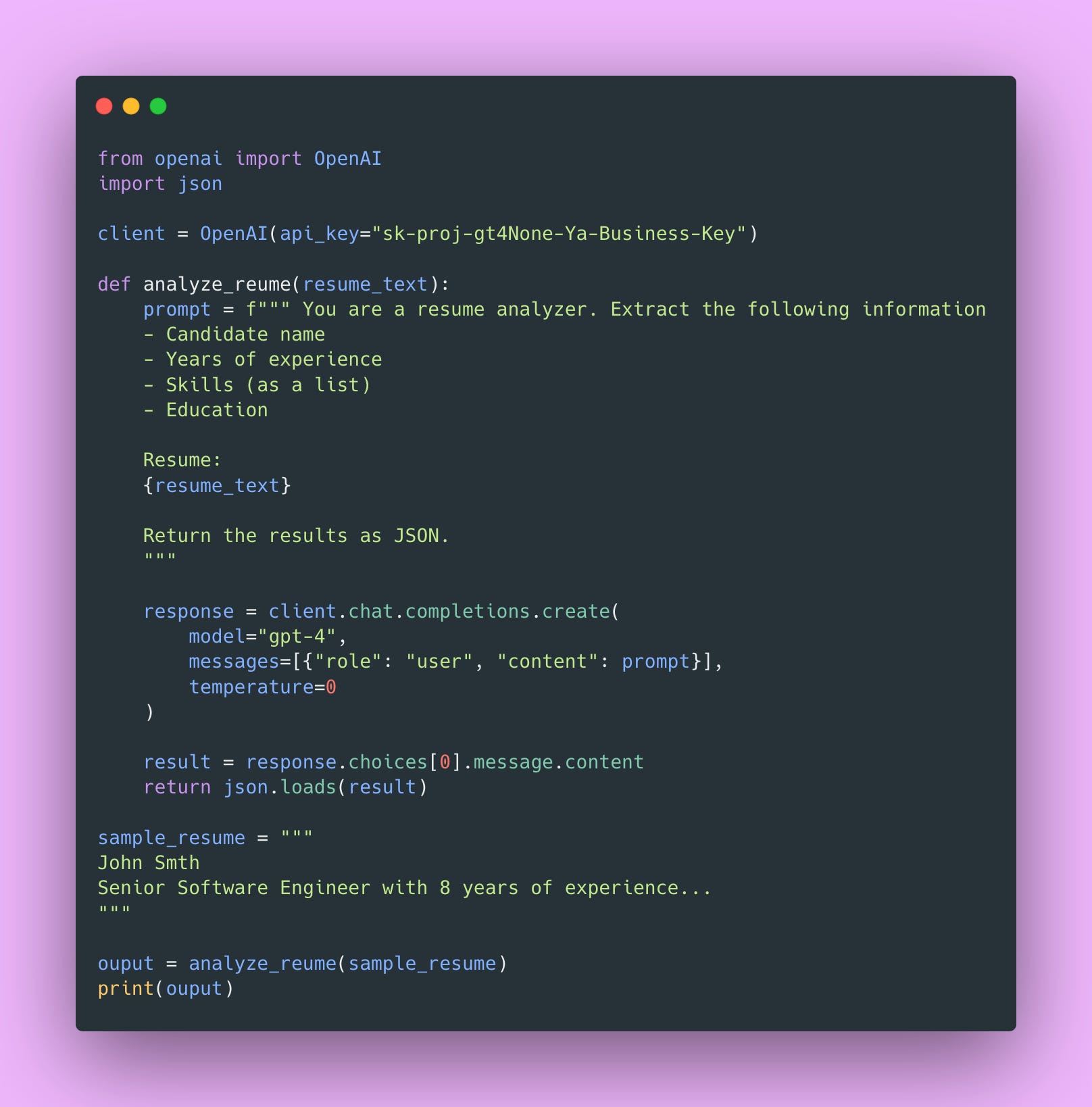
At first glance, this seems fine. It’s about 30 lines and it works. You can run it, get results, and show your team. So what’s the problem?
I’ll show you.
The Type Safety Issue
Quick question: what does `analyze_resume()` return?
You might say “a dictionary.” But what keys are in that dictionary? What are their types? Is `years_of_experience` an int or a string? Is `skills` a list of strings or a comma-separated string?
You have to read the prompt, hope the LLM returns what you asked for, and pray it’s consistent. There’s no contract, no schema, no guarantee. Also, your IDE can’t help you with autocomplete because it has no idea what you’re working with.
I’ve run into this exact issue before. I had a function that was supposed to return a structured response from an LLM, and I just assumed `experience_years` would be an integer. Made sense, right? Turns out the LLM sometimes returned “5 years” as a string, sometimes “5” as a string, and occasionally (I kid you not) “five” spelled out. My downstream code that tried to do `if experience_years > 3` crashed in three different ways depending on which format showed up.
If I can’t tell what this function returns without running it, neither can anyone else on my team. When the LLM randomly decided to format the output differently, we’ll have runtime errors that should’ve been caught way earlier.
The Security Nightmare
See the API key on line 5? That’s a production incident waiting to happen.
Early in my career, I was reviewing a PR from someone on my team. The code looked fine, tests passed, everything seemed great. But I noticed a hardcoded HuggingFace API token.
“Did you push this to the repo?” I asked.
“Yeah, but I’ll change it right after!”
My stomach dropped. “How many commits ago?”
“Like, two commits back.”
Here’s the thing. Git is like an elephant. It NEVER forgets. Even if you change a secret in a later commit, it’s still sitting there in your repo’s history. Anyone who clones the repository can see it with a simple `git log` command. If your repo is public (or gets accidentally made public), that secret is now out in the wild.
GitHub has secret scanning, but it’s not instantaneous. By the time you get the notification email, bots have already scraped your token and added it to a database somewhere.
Right now, there’s probably a data scientist somewhere waking up to a $3,000 OpenAI bill because a bot found their exposed API key in a public repo and has been hammering GPT-4 endpoints for the past 12 hours. The hacker running that bot doesn’t care about your project or your career. They just want free compute.
What to Do If You’ve Leaked a Secret
If you realized you’ve committed a secret to Git:
Revoke the key immediately.
Report the incident.
Check your billing ASAP (OpenAI keys, AWS keys, anything that costs money).
Generate a new one.
Use `git filter-branch` or BFG Repo-Cleaner to remove it from history.
Force push (coordinate with your team first or get someone from security to help you).
The Right Way to Handle Secrets
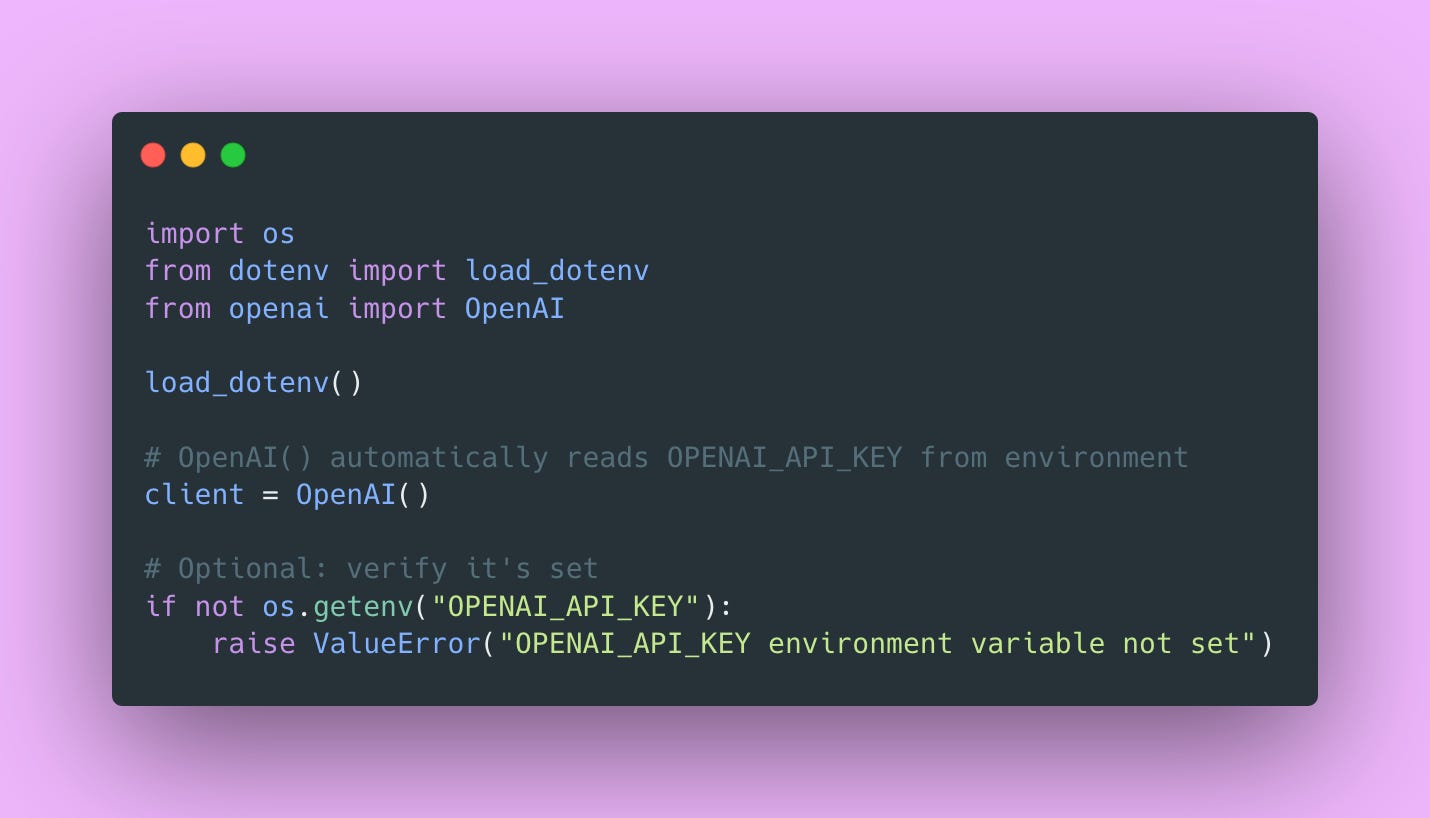
⚠️ And add `.env` to your `.gitignore` file. Always. Every single time. No exceptions. I have this muscle memory now where if I create a new repo, `.gitignore` is literally the first file I create, forget the README.
The Testing Dilemma
How do you test `analyze_resume()`? Right now, you can’t. Well, you can, but you’d have to actually call the OpenAI API every single time you run your tests. This creates several problems.
It costs money (every test run hits your API bill).
It’s slow (GPT-4 responses can take several seconds each).
It’s non-deterministic (same inputs potentially lead to different outputs).
It’s fragile (tests fail when OpenAI has an outage).
This function is tightly coupled to the external API. There’s no way to test your logic without actually calling OpenAI. Your tests are expensive, slow, and flaky. Your CI/CD pipeline would take forever to run, cost a fortune, and randomly fail for reasons that have nothing to do with your code.
The String Manipulation Problem
Let’s take a look at that prompt construction again 👇🏾

This is fine for a quick prototype. But what happens when you need to reuse this prompt logic in three different places? What if you want to A/B test different prompt versions? What if you want to keep track of which prompt version produced which results?
Right now, your prompt is just a string buried in a function. You can’t version it, can’t test different variations systematically, can’t share it across files without copy-pasting.
I’ve been in codebases where we had seven different versions of basically the same prompt because everyone just copied and tweaked the string instead of having a centralized place for prompt templates. When we needed to change something fundamental, we had to hunt through the entire repo. Not fun.
The Error Handling Setback
What happens when OpenAI’s API is down? What if you hit rate limits? What if the response isn’t valid JSON? What if the model returns null for a required field?
Right now, the answer is: your code crashes.

There’s no retry logic, no fallback behavior, no graceful degradation. Just exceptions waiting to blow up your application.
The Observability Obstacle
When something goes wrong in production (and it will), how do you debug it?
The current notebook has a `print` statement. That’s it. You have no logs, no metrics, no tracing. You can’t answer basic questions like:
How long do requests actually take?
Which prompts are performing poorly?
What’s our error rate?
Which inputs consistently cause failures?
How much are we spending on API calls?
You’re flying blind. I’ve been pulled into emergency debugging sessions where a service was failing intermittently. Having zero visibility into what’s happening is genuinely awful. You end up adding print statements, redeploying, waiting for it to fail again, checking logs, and repeating that cycle until you find the issue. It’s tedious and totally avoidable.
What Production-Ready Actually Means
I’ve thrown around the term “production-ready” a lot, but what does it actually mean?
Here’s my definition: production-ready code is code that you wouldn’t panic about if you got a Slack message saying it broke while you were in a meeting.
That means:
Reliable (it handles errors gracefully and recovers from failures).
Observable (you can see what it’s doing and diagnose problems quickly).
Maintainable (other people can understand and modify it, including future you).
Testable (you can verify it works without manual testing).
Secure (it doesn’t leak secrets or expose vulnerabilities).
Performant (it can handle your expected load, plus some buffer).
Notice I didn’t say perfect. Production-ready doesn’t mean bug-free. It means you’ve thought through the failure modes and built in safeguards.
Where We’re Going
Over the next four posts, we’re going to systematically fix every problem I just outlined. Here’s the roadmap 🧭.
Post 2: Treating Prompts Like Code with BAML
We’ll introduce BAML (a domain-specific language for LLM applications) and use it to add type safety and structure to our prompts. You’ll learn why treating prompts like untyped strings is asking for trouble.
Post 3: Testing Your LLM Applications (Without Going Broke)
We’ll build a testing strategy that doesn’t require calling OpenAI’s API for every single test. You’ll learn about mocking, test doubles, and how to test LLM applications in a way that’s actually maintainable.
Post 4: Self-Hosting LLMs with vLLM
We’ll set up vLLM (a high-performance inference engine) to self-host open-source models. You’ll learn when self-hosting makes sense, when it doesn’t, and how to actually do it with Docker and GPU support.
Post 5: The Complete Production Pipeline
We’ll bring everything together: Dockerize the application, set up CI/CD, add proper monitoring and logging, implement error handling and retries, and deploy it.
By the end of this series, you’ll have transformed a messy notebook into a production system that you’d actually want to maintain. More importantly, you’ll understand the principles behind each decision.
Homework - Audit Your Own Code

Before moving on to the next post, I want you to do an honest audit of your own LLM code (if you have any). If you don’t have LLM code yet, grab any data science notebook you’ve written recently.
Go through and honestly assess these problems.
Type safety: Can you tell what your functions return without running them?
Configuration: Are any secrets hardcoded? Did they ever make it into version control?
Testability: Can you test your logic without hitting external APIs?
String manipulation: Are your prompts scattered throughout your code as raw strings?
Error handling: What actually happens when things go wrong?
Observability: If this broke while you were away, could you figure out why within 15 minutes?
Be brutally honest with yourself. I’m not here to judge (I’ve written plenty of questionable notebook code over the years). But you can’t fix problems you don’t acknowledge.
Write down what you find. Take notes on which problems show up most often in your code. We’re going to address each one over this series.
In the next post, we’ll tackle type safety and string manipulation by introducing BAML and treating our prompts like the first-class citizens they deserve to be. We’ll add structure and sanity to our LLM applications. No more crossing your fingers and hoping the output is what you expect.
Happy coding 🚀!