

Random Sampling Is Sabotaging Your Models!
Using Diversity for Better Data Selection

Several months ago, my teammate spent some time debugging why our chatbot kept failing in production. The model worked perfectly in dev. We had a solid test set with 500 examples...or so we thought.
When we finally figured it out, we discovered our test set had 50 variations for the same edge case and completely missed the actual failure modes. Random sampling failed us 😭.
I used to randomly sample everything. Test sets? Random sample. Few-shot examples? Random sample. Active learning? You guessed it, random sample. It seemed like the fair, unbiased approach. Then I stumbled onto research about maximally diverse subsets, and my entire approach to data selection changed.
Turns out, there’s a whole body of research on how to do this properly, and it’s been hiding in plain sight. Let me show you what I learned (and the mistakes I made along the way).
What Even Are Maximally Diverse Subsets?
The concept is simpler than the name suggests. Imagine you have 1,000 data points and need to pick 50 of them. Random sampling might cluster all 50 data points in one corner of your feature space. Diverse sampling spreads these data points out so they actually represent your full dataset.
What’s interesting is that there are different ways to measure diversity, and each measurement has different meanings.
Maximum pairwise distance picks points as far apart as possible from each other. If your data clusters naturally (like images of cats vs dogs vs birds), this approach grabs representatives from each cluster.
Coverage-based selection makes sure you’re hitting different regions of your feature space. Think of it like ensuring every neighborhood in a city has at least one representative on a committee.
Determinantal Point Processes (DPPs) use a probabilistic approach borrowed from quantum physics. Yes, quantum physics 🤯. DPPs naturally repel similar items, and the math behind them is honestly beautiful once you get past the intimidating name.
Why Should You Care?
I see four places where diversity-aware sampling makes a huge difference in your day-to-day work.
Building test sets: You want test cases covering different scenarios, not 100 variations of the same thing.
Few-shot prompting: Show your LLM different patterns. Three diverse examples teach more than five similar ones (I tested this and loved the results).
Hallucination detection: When an LLM hallucinates, it generates diverse outputs. Measure that diversity to catch hallucinations.
Data pruning with DPPs: Shrink your dataset by keeping the interesting stuff and dropping redundant examples. Your training time will decrease which means your AWS bill won’t make you nervous by the end of the month 💸.
Creating Better Test Sets
I was building a test set for a computer vision model a couple years ago. We had 10,000 labeled images but budget to manually review only 500 for our test set. I did what seemed reasonable: random sampling.
The test set looked fine at first glance. But when we deployed to production, the model failed on certain types of images that never appeared in our test set. Random sampling had oversampled common scenarios and completely missed rare but important edge cases.
When I dug into it, about 30% of my test images showed basically the same scene because the training data skewed heavily in that direction. Diverse sampling would have caught this immediately.
Two methods fix this problem.
K-means clustering groups similar images together and picks representatives from each cluster. It’s fast and works great for medium-sized datasets. I use this one most often now.
MaxMin Selection greedily picks points far from already-selected points. It’s slower on large datasets but guarantees good coverage across your entire feature space. (For large datasets, combine it with clustering first - see Pitfall #2 for the efficient approach.)
Here’s what I should have done.
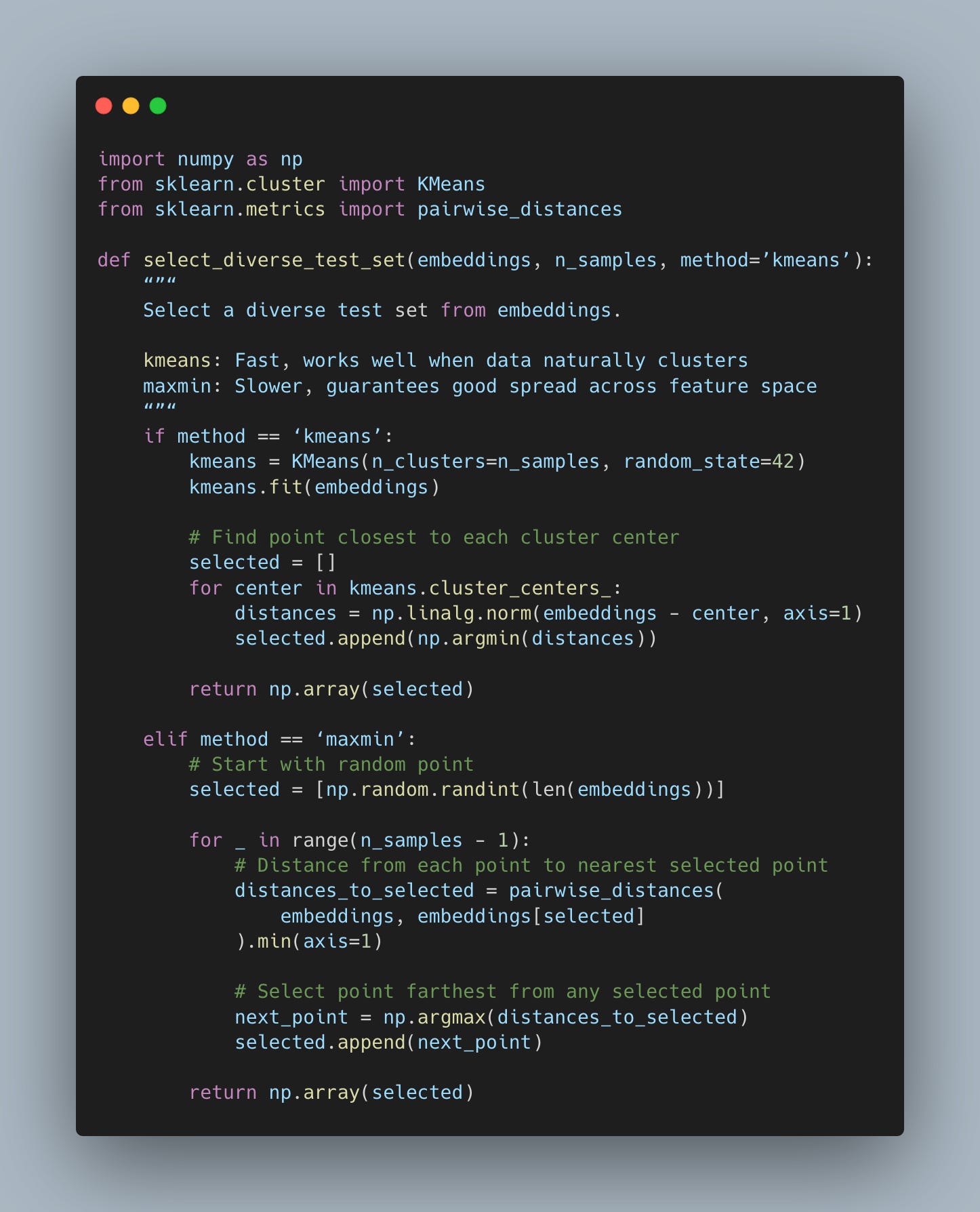
MaxMin ensures your test set spreads throughout your feature space. No clumping allowed.
My Few-Shot Selection Disaster
I was building a sentiment classifier for movie reviews. I had 1,000 labeled examples and could fit 5 in my prompt. I did the “smart” thing and used k-nearest neighbors to pick the 5 most similar examples to my test query.
My results were disappointing. The model kept making the same mistakes over and over.
Then I realized that all 5 examples were teaching the LLM basically the same pattern. They were all positive reviews using similar language. The model learned this one way to express positivity and nothing else.
I switched to Maximum Marginal Relevance (MMR), which balances similarity with diversity. The first example matches your query closely. Each subsequent example adds new information instead of repeating what the model already saw.
The improvement was immediate and obvious.
Here’s the code I wish I’d written the first time 👇🏾
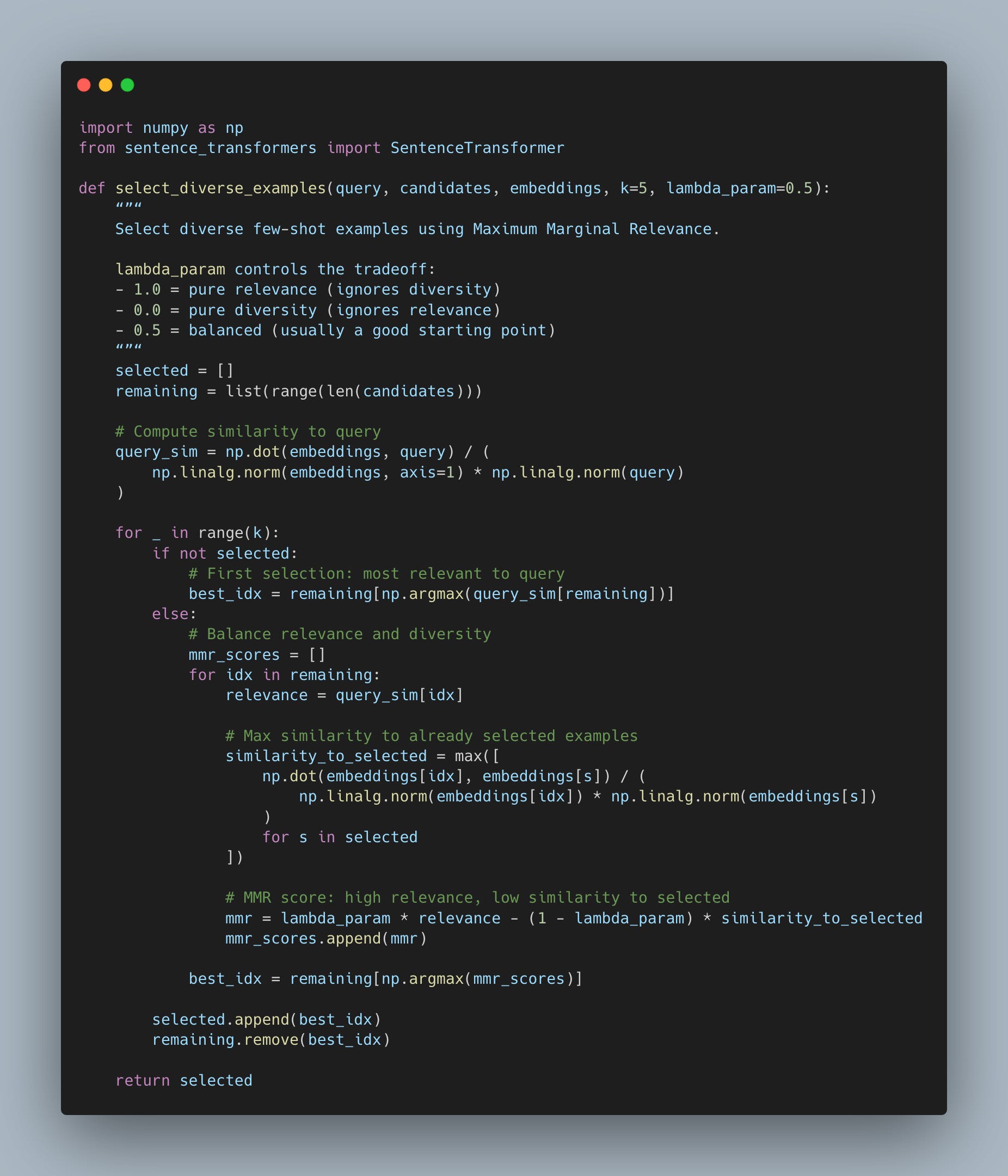
The paper, “Exploring the Role of Diversity in Example Selection for In-Context Learning”, confirmed what I saw in practice. MMR consistently beats pure similarity-based selection across different context sizes and similarity functions.
The Clever Hallucination Detection Trick
This one blew my mind when I first read about it. When an LLM hallucinates, it generates more diverse outputs across multiple samples. Why? Because it doesn’t actually know the answer, so it makes up different nonsense each time.
Think about it this way. Ask an LLM “What is the capital of France” five times. You’ll get five variations of “Paris” (maybe with different phrasing, but same core answer).
Now ask “What is the melting point of dragon scales?” five times. You’ll get five completely different made-up numbers because there’s no ground truth to anchor to. The diversity reveals the hallucination.
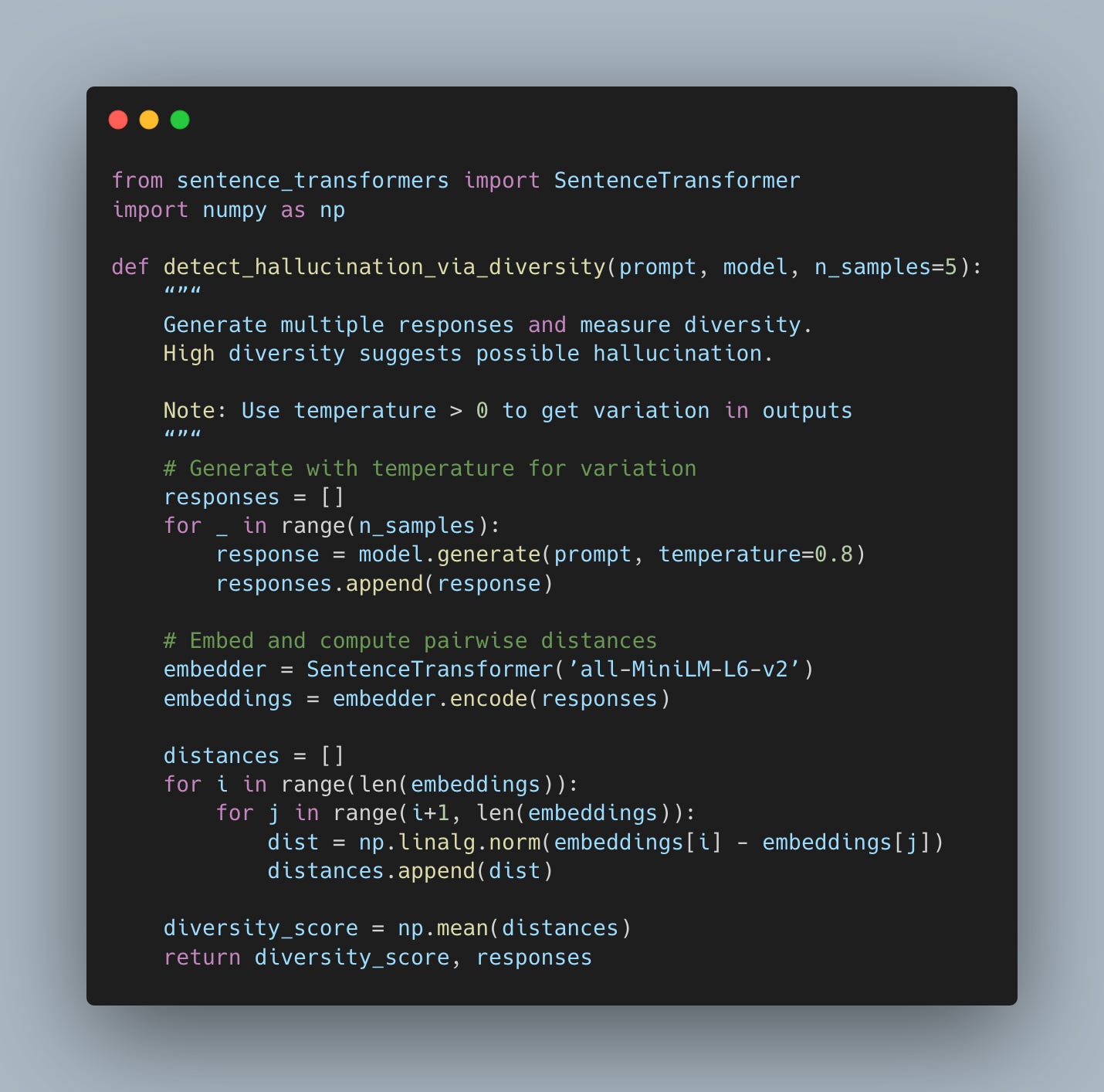
Several recent hallucination detection papers explore this approach. The intuition is solid. Confident and correct models give consistent answers. Hallucinating models generate different nonsense each time because there’s no ground truth to anchor to.
Data Pruning With Determinantal Point Processes
Imagine you have 100k training samples, but training is expensive and slow. Can you shrink your dataset to 10k samples while maintaining model performance? Random sampling gives you mediocre results. But what if you could select the 10k most diverse, informative examples?
That’s where DPPs shine.
DPPs model diversity through a kernel matrix (basically a similarity matrix). The probability of selecting a subset is proportional to the determinant of the kernel matrix for that subset. Larger determinants equal more diverse subsets.
The paper, “Post-training Large Language Models for Diverse High-Quality Responses”, used DPPs to train models that generate both high-quality AND diverse outputs. The results beat standard training approaches across multiple benchmarks.
Here’s a simplified implementation (this is the greedy approximation, exact sampling gets more complex).
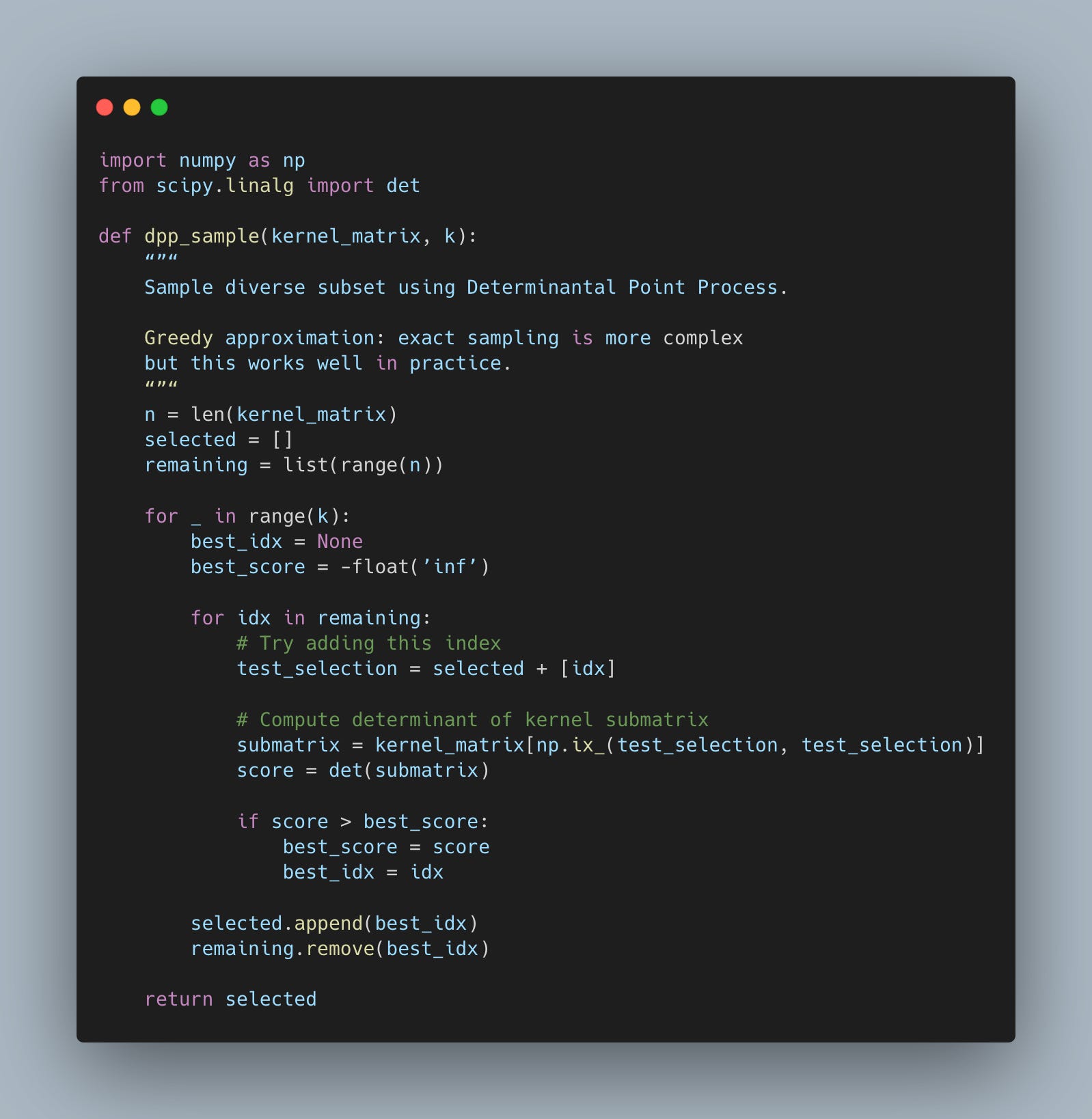
The beauty of DPPs is that they give you a principled probabilistic framework for diversity. You’re not just greedily picking points. You’re sampling from a distribution that naturally prefers diverse subsets.
For data pruning, this means you can train on 10-20% of your data and match (or sometimes beat!) the performance of training on the full dataset. Less storage, faster training iterations, lower compute costs. Pretty cool, right?
You may be eager to start applying maximally diverse subsets in your work, but there are a couple pitfalls you need to watch out for.
⚠️ Pitfall #1: Diversity Without Quality
I made this mistake because I was focused on getting diverse test samples, but I ended up with really low-quality examples in my test set. Some samples were near-duplicates with slight corruption. Others had labeling errors. One even had a cat labeled as “car” (still not sure how that happened).
Were they diverse? Sure. Were they useful? Nope.
The fix is straightforward. Filter for quality first, THEN apply diversity selection.
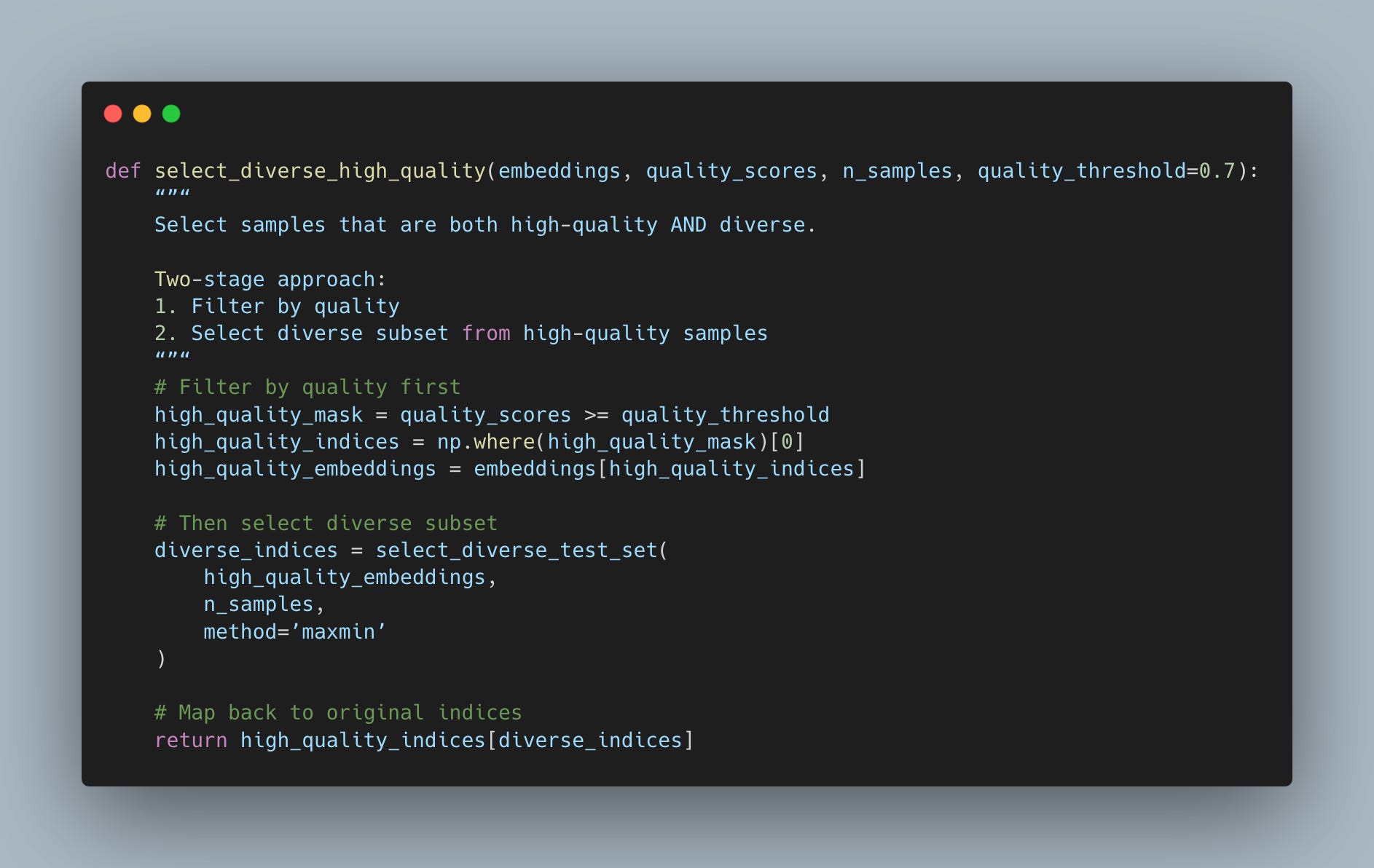
Just like any analytics, data science, or machine learning problem, you need clean data. Garbage in, garbage out, am I right?
⚠️ Pitfall #2: The Computational Cost
Computing pairwise distances for large datasets is expensive.
My first implementation processed 10,000 data points to select 100 examples. It took about half an hour.
The problem? I was computing ~50 million pairwise comparisons. That’s O(n²) complexity. When you’re iterating and experimenting, that adds up fast.
The fix? Use clustering to reduce the problem size.
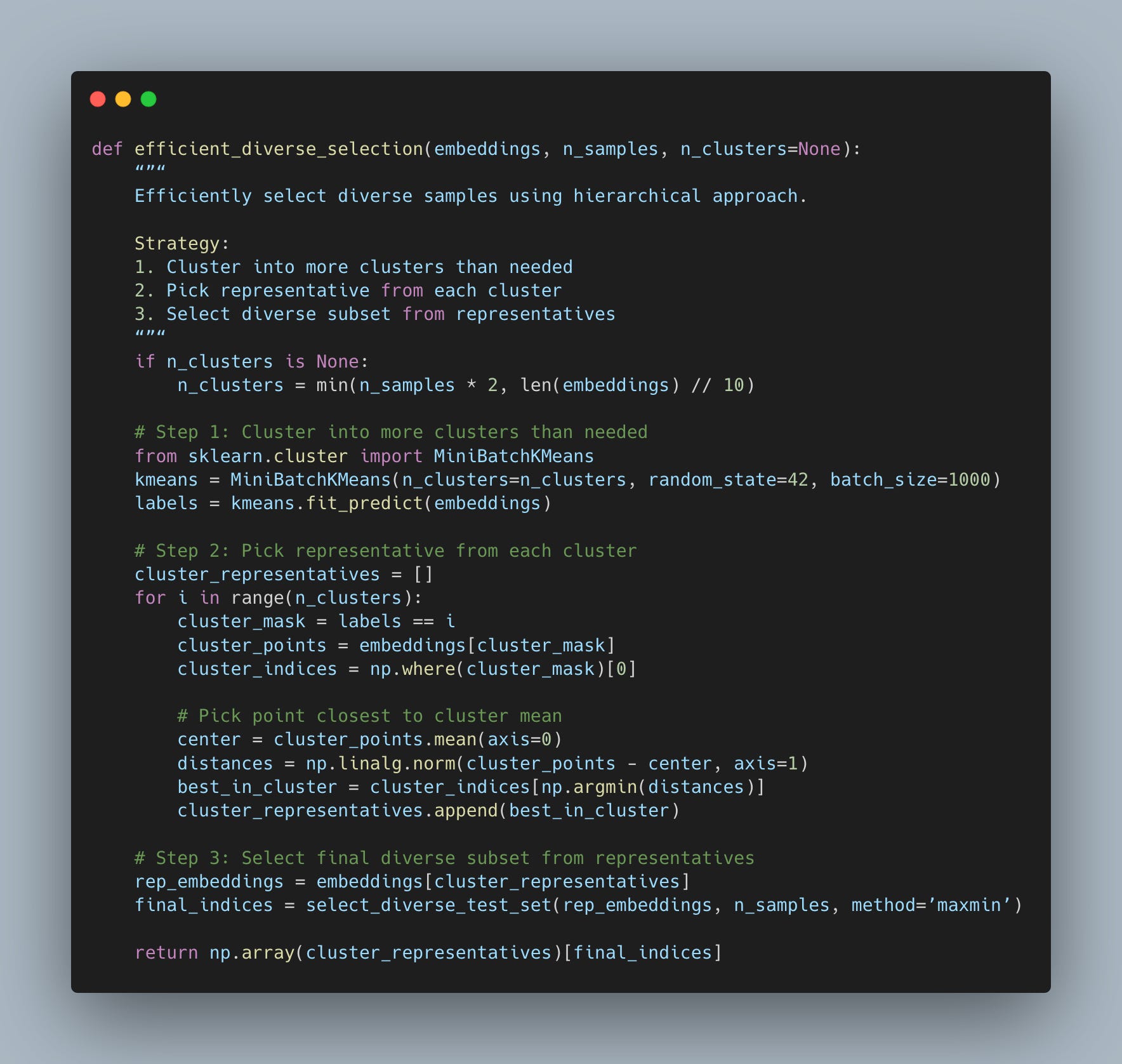
This is how the two-stage approach works.
Step 1: Cluster your data into more clusters than you need (maybe 2x your target). This step is O(n × k) where k is the number of clusters - much faster than O(n²).
Step 2: Pick one representative from each cluster - the point closest to each cluster center. Now you have maybe 200 representative points instead of 10,000.
Step 3: Run maxmin on the representatives to select your final diverse subset. Computing pairwise distances on 200 points is trivial compared to 10,000.
Why does this work for diversity? The clusters identify distinct regions of your feature space. One sample per cluster gives you coverage across different regions. Then maxmin on the representatives ensures you’re selecting the most spread-out samples from those regions.
This two-stage approach drops the runtime to under a few minutes for my use case. For 100k samples selecting 1k, this runs orders of magnitude faster than computing all pairwise distances.
Your teammates will appreciate you not hogging up all the resources for your experimental work 😉.
Note: Pick the Right Diversity Metric
Not all distance metrics are created equal, and choosing the wrong one can give you weird results.
Euclidean distance works for continuous embeddings where magnitude matters. I use this for image embeddings from ResNet or similar models.
Cosine distance works better for normalized embeddings where direction matters more than magnitude. I default to this for text embeddings from sentence transformers.
Semantic entropy captures meaning-level diversity. This requires clustering semantically equivalent outputs first. It’s more complex but sometimes worth it.
Your use case may result in using different distance metrics, and that’s fine as long as you’re aware that different metrics can render you different results.
The Numbers Don’t Lie
The research on diversity-aware sampling keeps getting better, and the results are honestly kind of exciting.
The February 2025 “Diversity as a Reward” paper showed a 27% improvement on math reasoning tasks. They used less than 10% of the original training data and got BETTER results. That’s awesome! Less data, less compute, better performance.
The few-shot learning improvements are equally impressive. The 2025 In-Context Learning paper showed consistent gains across different context sizes and similarity functions. No additional training required. Just change how you select examples.
The alignment work from “Efficient Alignment of Large Language Models via Data Sampling” demonstrated that you can match full-dataset performance using less than 10% of the data. Fewer labels to collect, less compute for training, faster iteration cycles. That’s a win every time.
These results come from different teams working on different models tackling different tasks. The pattern holds across domains. Diversity matters.
However, it’s not always the answer.
When Not To Use Diversity
Case 1: Debugging Specific Failures
Your model consistently chokes on questions about historical dates. You don’t want diverse examples. You want MORE historical date examples to understand the failure pattern.
Case 2: Narrow Specialization
You’re fine-tuning a model to generate SQL queries for your company’s specific database schema. You want homogeneous training data that teaches one thing really well. Diversity would dilute the signal.
Case 3: Consistency Checking
You’re testing whether slight input variations produce wildly different outputs. You need similar inputs on purpose.
Diversity is a tool for coverage and robustness. But sometimes you need focus instead.
Your Action Plan for Next Week
If you want to get started, start small by creating a function to help you select diverse test sets.
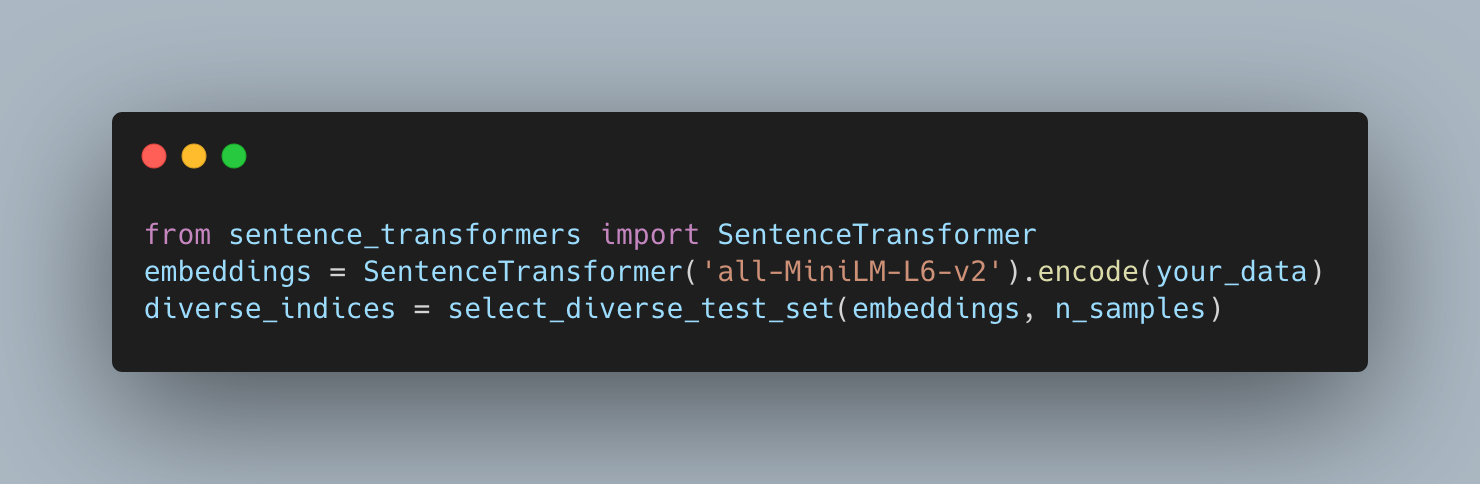
With this, you’ll build better test sets, select better few-shot examples, and catch failures earlier. Hopefully, you can spend less time debugging and more time creating.
Continued Reading
If this post clicked with you and you want to dive deeper, check out these papers. They’re all recent and fairly straightforward.
“Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data” (2025)
https://arxiv.org/abs/2502.04380
“Post-training Large Language Models for Diverse High-Quality Responses” (2025)
https://arxiv.org/abs/2509.04784
“Exploring the Role of Diversity in Example Selection for In-Context Learning” (2025)
https://www.arxiv.org/abs/2505.01842
“Efficient Alignment of Large Language Models via Data Sampling” (2024)
https://arxiv.org/abs/2411.10545
Code Available Here 📎
All code snippets from this post are available in this GitHub repo.
Feel free to experiment with the MMR implementation and diversity parameter tuning!
Happy coding ✨